The agent works, gets partway through, exits. The loop feeds it back in. The agent sees its own git history from previous attempts. It tries a different approach. It iterates.
This sounds too simple to be useful. In practice, it is extremely effective for mechanical tasks with clear success criteria. “All tests pass” is a clear success criterion. We use this pattern for our self-healing retry loop — the agent does not retry the same fix, it analyzes what failed and tries from a different angle.
The BMAD Method
BMAD uses 12 specialized agents across four phases: Analysis, Planning, Solutioning, and Implementation. The key insight we took from BMAD is document sharding. Do not feed the agent a 47-file work plan and expect coherent execution. Break the plan into atomic shards where each shard fits within one context window. Process shard 1, verify it, then process shard 2.
Devin’s Knowledge System and Mem0
Devin AI uses DeepWiki and Devin Search to give their agent deep project knowledge before touching any code. This gave us the idea for structured project memory with three distinct knowledge types:
- Entity-relationship facts — how modules connect (“auth module uses JWT via jsonwebtoken@9.x, /api/v1/users is protected by authMiddleware”)
- Temporal facts — what changed as a result of specific tickets (“since PLANE-a1b2, the login endpoint has rate limiting”)
- Failed approaches — what was tried and why it did not work (“express-slow-down is not installed — use express-rate-limit which is already in dependencies”)
Mem0 — the open-source memory layer — adds semantic search on top of this. When an agent starts a new ticket about login validation, Mem0 surfaces memories from every previous ticket that touched authentication, even if the keywords are completely different.
GSD, Superpower, OpenSpec, Speckit, Oh-My-Claude-Code, Gumloop AI
Every method in this space, when you strip it back, converges on the same principle: define done precisely before any code is written. GSD and Superpower emphasize spec-first development. OpenSpec and Speckit focus on structured acceptance criteria as the agent’s contract. Oh-My-Claude-Code demonstrated the plugin ecosystem — hooks, skills, slash commands as composable primitives. Gumloop demonstrated visual workflow orchestration for complex agent pipelines.
We did not invent a new method. We took the best insight from each and combined them into one system.
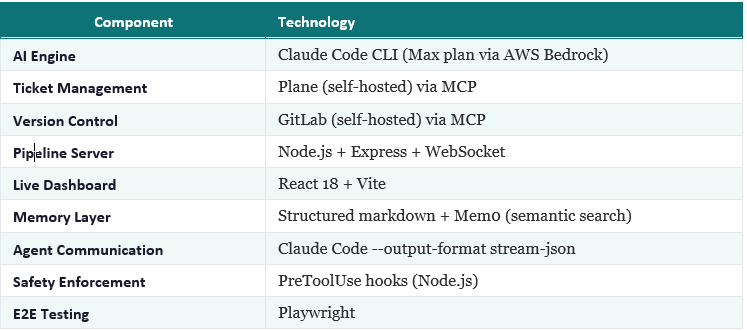
The Architecture
The Trigger
A Plane ticket gets the ai-ready label. This fires a webhook to our Node.js server. The server validates the signature, extracts the ticket ID and project ID, and spawns the Orchestrator Agent via the Claude Code CLI:

The –output-format stream-json flag gives NDJSON output — every event (text deltas, tool calls, tool results) streamed as a structured JSON line. The server parses these and broadcasts them via WebSocket to the live dashboard.
No Anthropic API key needed. This runs on our Claude Code subscription through AWS Bedrock.
The Orchestrator Agent
The Orchestrator is the brain. It reads the full ticket and project context via the Plane MCP server, scores complexity on a 0–10 scale, and makes a routing decision:
- Route A — Escalate (complexity ≥ 9, ambiguous, or critical path like auth/payments/DB): Agent posts a question on the ticket, sets state to “Needs Clarification,” and stops. Human reply fires the comment webhook, server re-triggers with –resume {session_id}.
- Route B — Solo (complexity 0–5, clear ticket, not critical path): One agent handles everything — plan, code, test, commit, PR.
- Route C — Team (complexity 6–8, multi-layer change): Orchestrator spawns specialized subagents via the Agent tool, each in its own isolated context window.
The Agent Team
When Route C is selected, three agents coordinate:
The Coder receives the work plan — but not all at once. It receives one shard at a time. For each file, it reads the file fully, makes the change, then reads it back immediately to verify the edit landed correctly before moving to the next file.
The Tester runs the test suite with a baseline capture first — so pre-existing failures are excluded from the verdict. If tests fail, it self-heals up to three times, each time from a fresh mental model. Each failed approach is recorded in the progress file so subsequent retries never repeat the same dead-end fix.
The Reviewer grades the output with calibrated examples baked into its prompt — concrete examples of PASS, PASS with notes, and BLOCK. If BLOCK, specific issues are fed back to the Coder as a targeted fix shard. One extra iteration. If still blocked, the pipeline escalates to human.
The Memory System
Every project has a structured memory file at .claude/memory/{project_id}.md. Read at the start of every run, written at the end of every successful run. Organized into five knowledge types: entity-relationship facts, temporal facts, failed approaches, operational facts, and a rolling log of recent tickets.
The progress file at {run_dir}/claude-progress.txt is separate — per-run, not per-project. It captures the current phase, completed steps, files changed, failed approaches, decisions made, and what is left to do.
The Dashboard
The live dashboard streams everything in real time via WebSocket. Left panel: chronological worklog — every phase change, tool call, agent decision, with expandable detail. Right panel: live terminal output and command history with durations. Built to mirror Devin’s UI — because that was the benchmark we aimed for.
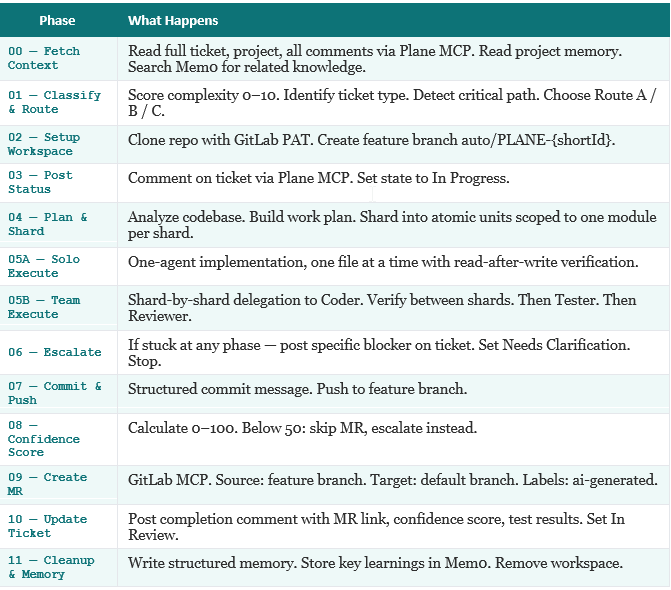
The 12 Pipeline Phases
Every ticket run goes through a structured sequence of phases, each tracked in the progress file: